散列表
散列(Hash Table)表又称哈希表,这种数据结构的特点是:数据元素的关键字和它在表中的存储地址直接相关。关键字与存储地址对应的关系的函数称为哈希函数
哈希函数:Address=Hash(key)
- 哈希是一种以常数平均时间执行插入、删除和查找的技术,但是,不支持元素排序和查找最小(大)值的操作
- 哈希函数是一种映射关系,很灵活,任何关键字通过它的计算,返回的值都落在表长允许的范围之内即可
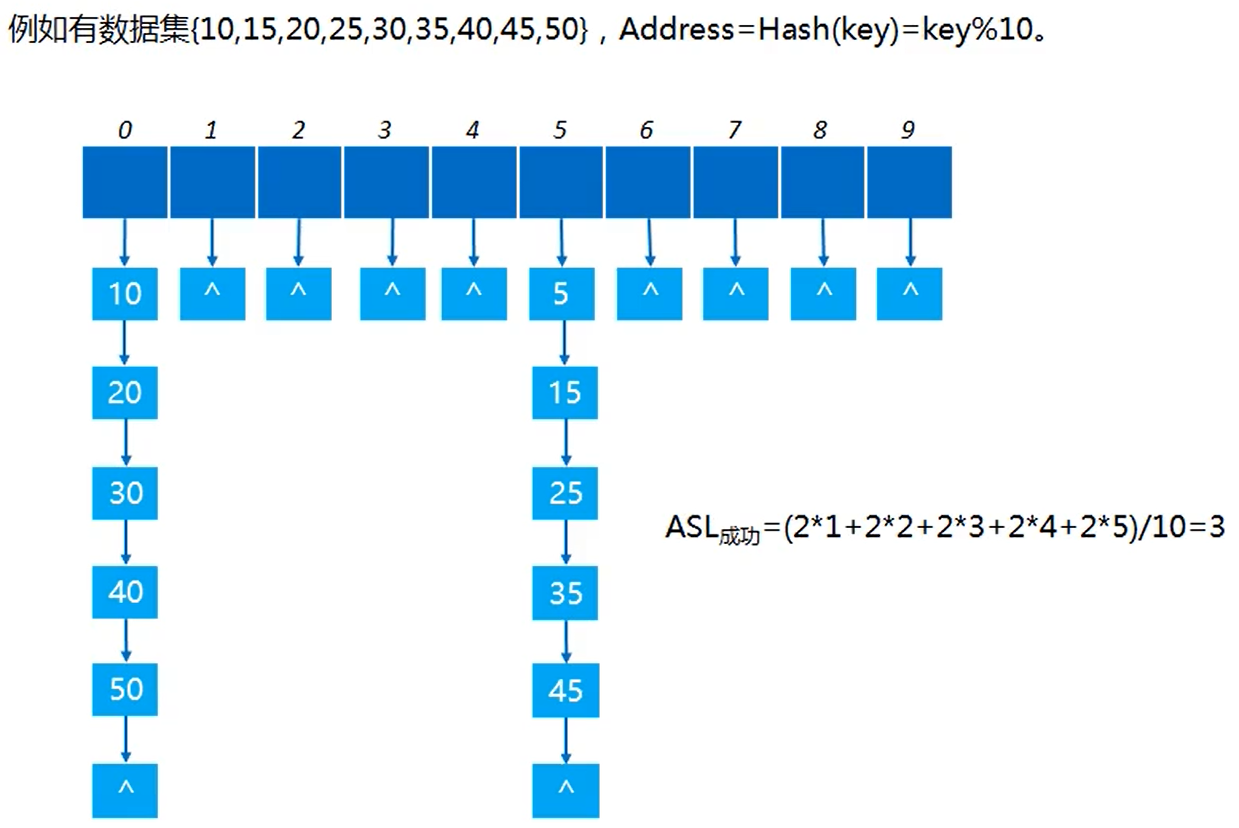
- 对于不同的关键字,可能得到相同的哈希地址,这种现象称为冲突;哈希地址相同的关键字称为同义词
- 处理冲突的方法有四种:链地址法、开放定址法、再散列表和建立公共溢出区
- 哈希表的装填因子(表中记录数/表长)越大,关键字冲突的可能性越大,同义词越多,查找效率可能更低

散列函数设计
除留余数法:Hash(key)=key%p
- 如果散列表的表长为m,p为小于等于m的最大质数,再一般情况下,对质数取余会让冲突更少,数据元素在散列表的分布更均匀
- 质数又称素数,除了1和自身,不能被其它自然数整除的数(1,3,7,13,17,19…….)
直接定址法:Hash(key)=a*key+b,a和b为常数
- 这种方法的计算简单,不会产生冲突,适合关键字的分布比较连续的情况,如果关键字分布不连续,空位较多,则会造成存储空间的浪费
数字分析法
- 根据关键字的特点,从数值中截取分布比较均匀的若干位作为散列地址,在应用开发中,还要结合除留余数法一起使用
平方取中法
- 根据关键字的特点,取关键字的平方值的中间若干位作为散列地址。这种方法得到的散列表地址和关键字的每个位都有关系,适用于关键字的取值不够均匀或小于散列地址所需的位数
随机数法
- 选择一个随机函数,用关键字作为随机函数的种子,返回值位散列地址,即Hash(key)=radmom(key),可结合除留余数法一起使用
散列函数的设计原则
- 清除关键字分布情况
- 散列表的大小要合理,太大浪费空间,太小则会产生太多的同义词
- 散列表中的数据分布要均匀,不要形成堆积(聚集)
- 散列函数代码要精简
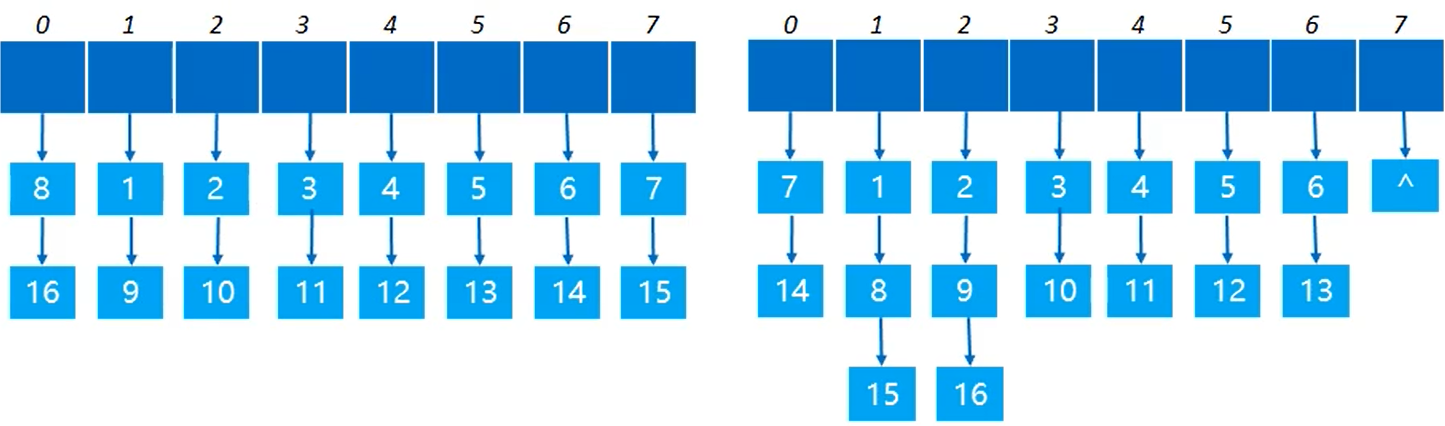
开放定址法
开放定址法
- 如果有冲突发生,那么就尝试其他的存储单元,直到找出空的单元为止
- Hi=(Hash(key)+di)%m i=0,1,2,3,4,…,m-1,Hash(key)为散列函数,m为散列表长,di为增量序列(i为第i次发生冲突,0表示没冲突),有三种取法:
- 线性探测法,di=0,1,2,3,4,……,m-1
- 平方探测法,di=02,12,-12,22,-22,32,-32,……,k2,-k2(k<=m/2)
- 伪随机序列法,di是一个伪随机的序列,如0,3,-2,5,7,-5,-7,9……
再散列
准备多几个散列函数,如果发生了冲突,就用下一个散列函数计算一个新的地址,直到不冲突为止



