插入排序
直接插入排序
采用顺序查找法查找插入位置
// ptr第一个元素是哨兵不存放数据,num是包括哨兵在内总数
void sort(int *ptr,int num)
{
int i=0;
int j=0;
for(i=2;i<num;i++){
if(ptr[i]<ptr[i-1]){
ptr[0]=ptr[i];
for(j=i-1;ptr[0]<ptr[j];j--){
ptr[j+1]=ptr[j];
}
ptr[j+1]=ptr[0];
}
}
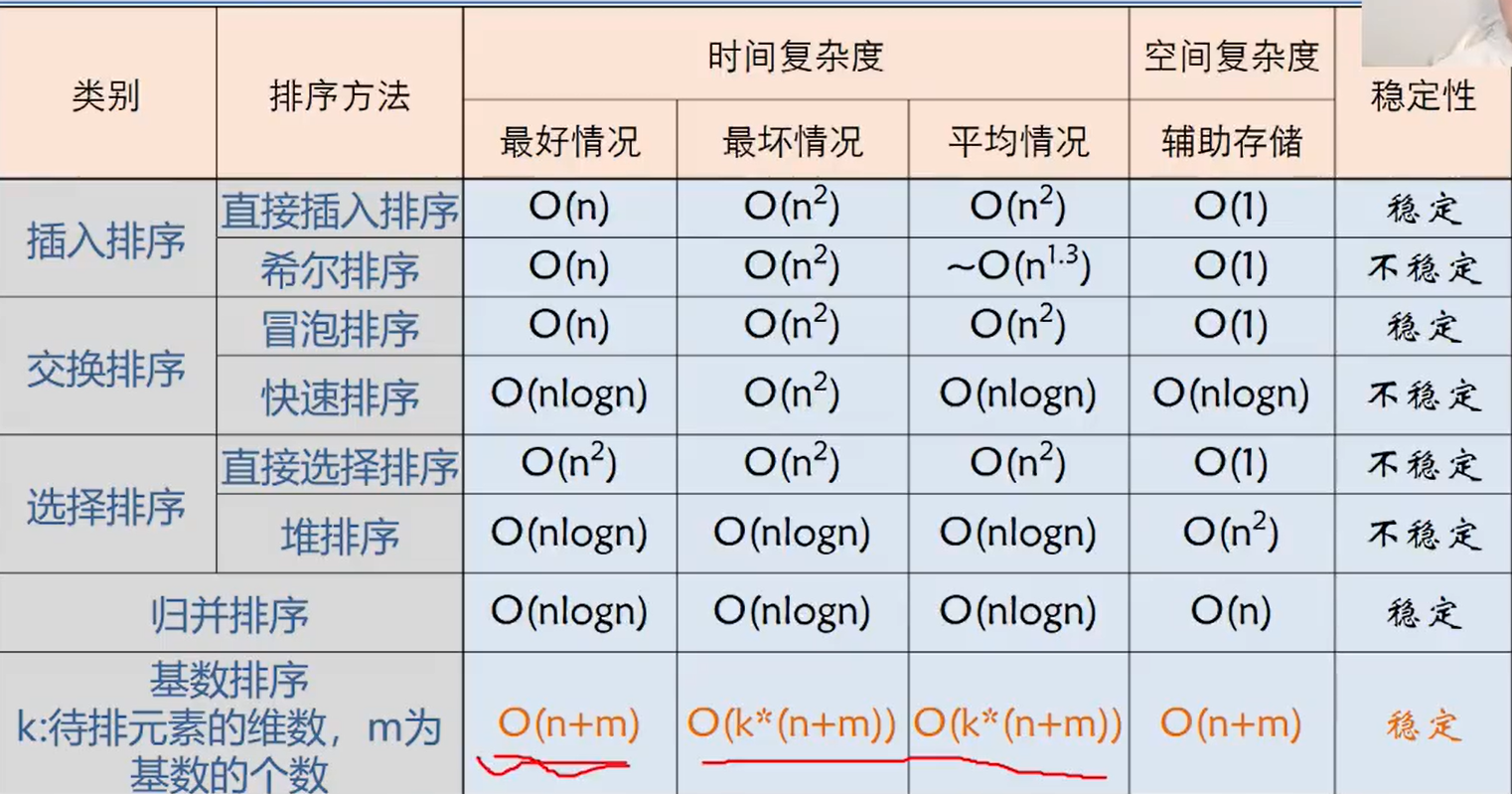
}时间复杂度结论
- 原始数据越接近有序,排序速度越快
- 最坏情况下(输入数据是逆有序的) Tw(n)=O(n2)
- 平均情况下,耗时差不多是最坏情况的一半 Te(n)=O(n2)
- 要提高查找次数
- 减少元素的比较次数
- 减少元素的移动次数
折半插入排序
折半查找比顺序查找快,所以折半插入排序就平均性能来说比直接插入排序要快
- 时间复杂度为O(n2)
- 空间复杂度为O(1)
- 稳定的排序方法
// ptr第一个元素是哨兵不存放数据,num是包括哨兵在内总数
void sort(int *ptr,int n)
{
int i,j;
int low,high,mid;
for(i=2;i<n;i++){
ptr[0]=ptr[i];
low=1;
high=i-1;
while(high>=low){
mid=(low+high)/2;
if(ptr[0]>ptr[mid])
low=mid+1;
else
high=mid-1;
}
for(j=i-1;j>=high+1;j--){
ptr[j+1]=ptr[j];
}
ptr[j+1]=ptr[0];
}
}它所需要的关键码比较次数与待排序对象序列的初始排序无关,仅依赖与对象个数。在插入第i个对象时,需要经过[log2i]+1次关键码比较,才能确定它应插入的位置;
- 当n较大时,总关键码比较次数比直接插入排序的最坏情况要好得多,当比其最好情况要差;
- 在对象的初始排序已经按关键码排好序或接近有序时,直接插入排序比折半插入排序执行的关键码比较次数要少;
希尔排序
- 一次移动,移动位置较大,跳跃式地接近排序后的最终位置
- 最后一次只需要少量移动
- 增量序列必须是递减的,最后一个必须是1
- 增量序列应该是互质的
增量序列
- 定义增量序列Dk: DM>DM-1>DM-2>…>D1=1
- 对每个Dk进行“Dk-间隔”插入排序
void sort(int *ptr,int n,int span)
{
int i,j;
for(i=span+1;i<n;i++){
ptr[0]=ptr[i];
if(ptr[i-span]>ptr[0]){
for(j=i-span;j>0&&ptr[j]>ptr[0];j=j-span){
ptr[j+span]=ptr[j];
}
ptr[j+span]=ptr[0];
}
}
}
void xiersort(int *ptr,int n,int *array,int arraysize)
{
int i=0;
for(i=0;i<arraysize;i++){
sort(ptr,n,array[0]);
}
}
int main()
{
// 第一个元素为哨兵
int ptr[]={0,4,39,23,71,15,36,12,31,44,32,18,17,46};
// 增量序列
int array[3]={1,3,5};
for(int i=1;i<sizeof(ptr)/4;i++){
printf("%d ",ptr[i]);
}
printf("\n");
xiersort(ptr,sizeof(ptr)/4,array,3);
for(int i=1;i<sizeof(ptr)/4;i++){
printf("%d ",ptr[i]);
}
printf("\n");
return 0;
} 希尔排序算法效率与增量序列的取值有关
- Hibbard增量序列
- Dk=2k-1相邻元素互质,如15,7,3,1
- 最坏情况:Tworst=O(n3/2)
- 猜想:Tavg=O(n5/4)
- Sedgewick增量序列
- {1,5,19,41,109,…}
- 猜想:Tavg=O(n7/6) Tworst=O(n4/3)
希尔排序算法分析
- 时间复杂度是n和d的函数 O(n1.25)~O(1.6n1.25) —— 经验公式
- 空间复杂度为O(1)
- 是一种不稳定的排序方法
- 最后一个增量值必须为1
- 不宜在链式存储结构上实现
交换排序
冒泡排序
// 每躺结束时,不仅能挤出一个最大值到最后面位置,还能同时部分理顺其他元素
void sort(int *ptr,int n)
{
int i,j;
int x;
int flag=1; // 如果有其中的一趟中没有发生过交换就代表序列已经排好了,不需要进行后面的比较
for(i=1;i<n&&flag==1;i++){
flag=0;
for(j=0;j<n-i;j++){
if(ptr[j]>ptr[j+1]){
flag=1;
x=ptr[j];
ptr[j]=ptr[j+1];
ptr[j+1]=x;
}
}
}
}冒泡排序总结
- n个记录,总共需要n-1躺
- 第m躺需要比较n-m次
- 最好情况:正序;最坏情况:逆序
冒泡排序算法评价
- 冒泡排序最好时间复杂度是O(n)
- 冒泡排序最坏时间复杂度为O(n2)
- 冒泡排序平均时间复杂度为O(n2)
- 冒泡排序是稳定的
快速排序
基本思想:通过一趟排序,将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录进行排序,以达到整个序列有序
具体实现:选定一个中间数作为参考,所有元素与之比较,小的调到其左边,大的调到右边
中间数:可以是第一个数、最后一个数,最中间一个数
// ptr[0]是哨兵
int psort(int *ptr,int low,int high)
{
ptr[0]=ptr[low];
while(low<high){
while(low<high&&ptr[0]<ptr[high])
high--;
ptr[low]=ptr[high];
while(low<high&&ptr[0]>ptr[low])
low++;
ptr[high]=ptr[low];
}
ptr[low]=ptr[0];
return low;
}
void sort(int *ptr,int low,int high)
{
int point;
if(low<high){
point=psort(ptr,low,high);
}else{
return;
}
sort(ptr,low,point-1);
sort(ptr,point+1,high);
}- 时间复杂度
- 可以证明,平均计算时间是O(nlog2n)
- sort() : O(log2n)
- psort() : O(n)
- 实验结果表明:就平均计算时间而言,快速排序是我们所讨论的所有内排序方法中最好的一个
- 可以证明,平均计算时间是O(nlog2n)
- 空间复杂度
- 在平均情况下,需要O(logn)的栈空间
- 最坏情况下:栈空间可达O(n)
- 快速排序是一种不稳定的排序方法
- 快速排序不适于对原本有序或基本有序的记录序列进行排序
- 划分元素的选取是影响时间性能的关键,输入数据次序越乱,锁选划分元素值的随机性越好,排序速度越快,快速排序不是自然排序方法,最坏情况下时间复杂度是O(n2)
选择排序
直接选择排序
在待排序的数据中选出最大(小)的元素放在最终的位置
- 首先通过n-1次关键字比较,从n个记录中找出关键字最小的记录,将它与第一个记录交换
- 再通过n-2次比较,从剩余的n-1个记录中找出关键字次小的记录,将它与第二个记录交换
- 重复上述操作,共进行n-1趟排序后,排序结束
void sort(int *ptr,int n)
{
int min;
int temp;
for(int i=0;i<n-1;i++){
min=i;
for(int j=i+1;j<n;j++)
if(ptr[min]>ptr[j])
min=j;
if(min!=i){
temp=ptr[i];
ptr[i]=ptr[min];
ptr[min]=temp;
}
}
}- 时间复杂度
- 记录移动次数
- 最好情况:0
- 最坏情况:3(n-1)
- 比较次数:无论待排序列处于什么状态,选择排序所需进行的比较次数相同
- 记录移动次数
- 算法稳定性
- 简单选择排序是不稳定排序
堆排序

从堆的定义可以看出,堆实质是满足如下性质的完全二叉树:二叉树中任一非叶子结点均小于(大于)它的孩子结点
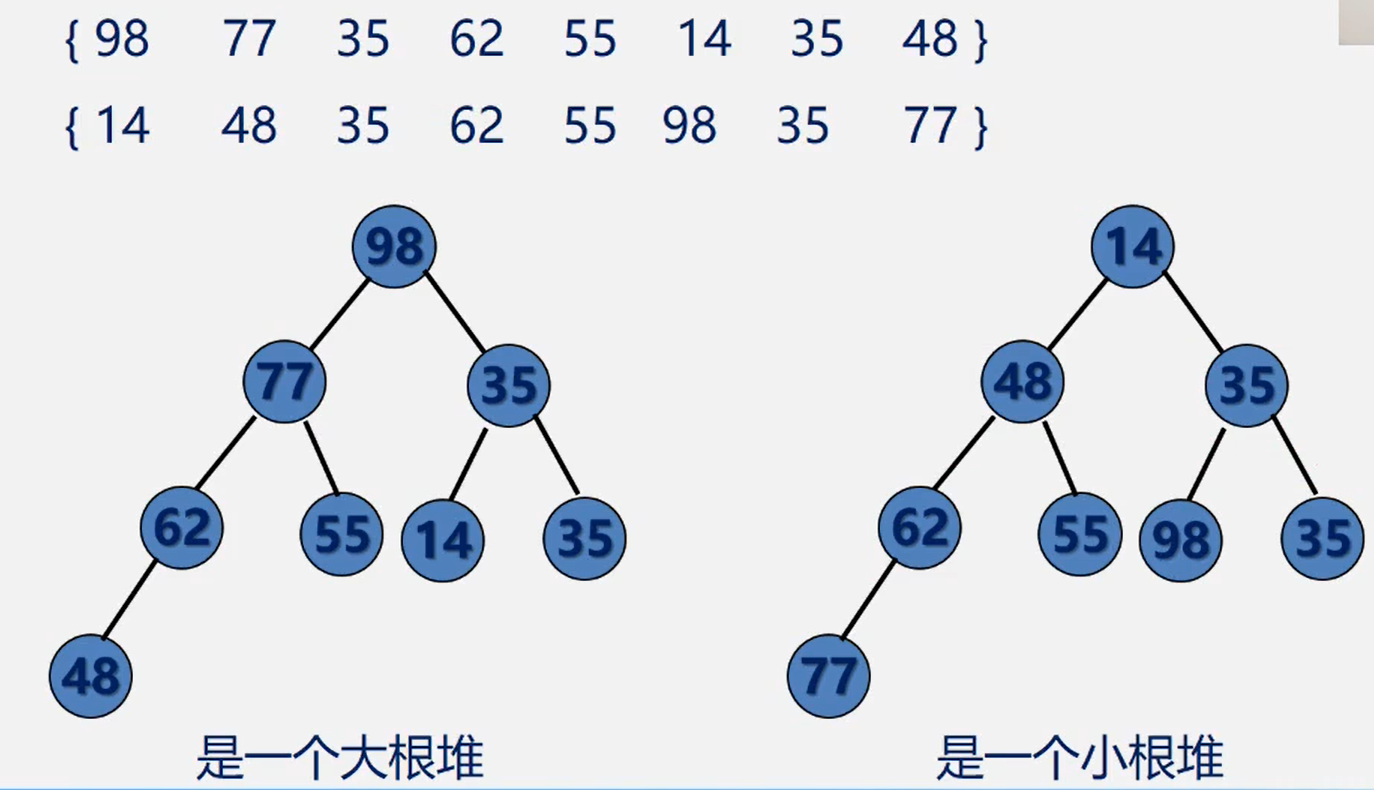
堆排序:若在输出堆顶的最小值(最大值)后,使得剩余n-1个元素的序列重又建成一个堆,则得到n个元素的次小值(次大值)……如此反复,便能得到一个有序序列,这个给过程称之为堆排序
实现堆排序需解决两个问题
- 如何由一个无序序列建成一个堆
- 如何在输出堆顶元素后,调整剩余元素为一个新的堆
如何在输出堆顶元素后,调整剩余元素为一个新的堆
- 输出堆顶元素之后,以堆中最后一个元素替代之;
- 然后将根结点值与左、右子树的根结点值进行比较,并与其中小者进行交换;
- 重复上述操作,直至叶子结点,将得到新的堆,称这个从堆顶至叶子的调整过程为“筛选”
如何由一个无序序列建成一个堆
只需依次将以序号为n/2,n/2-1,……,1的结点为根的子树均调整为堆即可
即:对应由n个元素组成的无序序列,“筛选”只需从第n/2个元素开始。
void adjustheap(int *ptr,int left,int right)
{
int root;
root=ptr[left];
for(int i=left*2;i<=right;i=i*2){
if(i<right&&ptr[i]<ptr[i+1])
i++;
if(root>ptr[i])
break;
ptr[left]=ptr[i];
left=i;
}
ptr[left]=root;
}
// ptr[0]是哨兵不存储数据,n是除哨兵之外数据的个数
void sort(int *ptr,int n)
{
int temp;
// 将无序序列按堆进行排序
for(int i=n/2;i>=1;i--){
adjustheap(ptr,i,n);
}
for(int i=n;i>1;i--){
temp=ptr[i];
ptr[i]=ptr[1];
ptr[1]=temp;
adjustheap(ptr,1,i-1);
}
}- 堆排序的时间主要耗费在建初始堆和调整堆新堆时进行的反复筛选上。堆排序在最坏情况下,其时间复杂度也为O(nlog2n),这是堆排序的最大优点。无论待排序列中的记录时正序还是逆序排列,都不会使堆排序处于“最好”或“最坏”的状态
- 另外,堆排序仅需一个记录大小供交换用的辅助存储空间
- 然而堆排序是一种不稳定的排序方法,它不适用于待排序记录个数n较少的情况,但对于n较大的文件还是很有效的
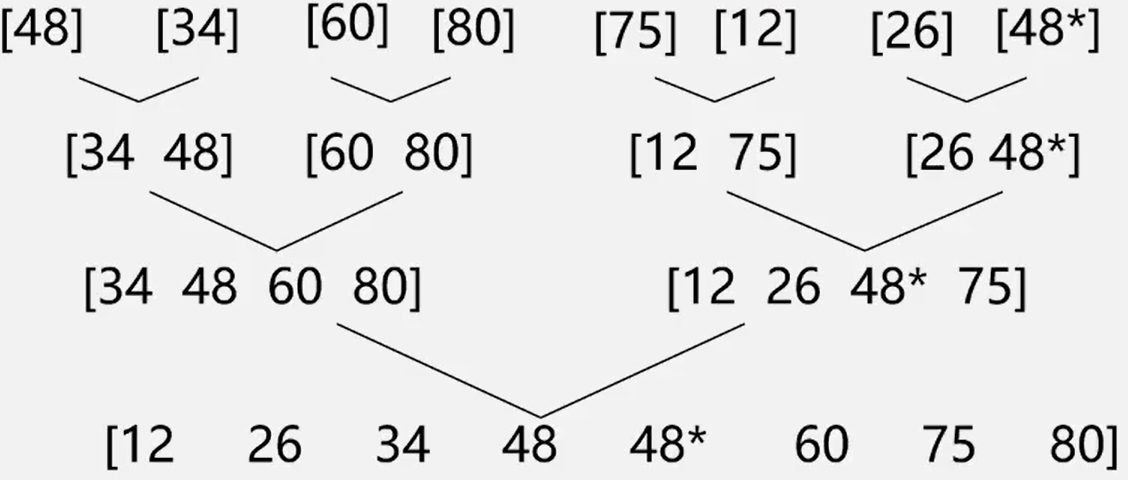
归并算法
整个归并排序仅需log2n趟
void merge(int *ptr,int left,int mid,int right,int *data)
{
int i=0;
int j=0;
int t=left;
for(i=left,j=mid+1;i<=mid&&j<=right;){
if(ptr[i]>ptr[j]){
data[t++]=ptr[j++];
}else{
data[t++]=ptr[i++];
}
}
while(i<=mid){
data[t++]=ptr[i++];
}
while(j<=right){
data[t++]=ptr[j++];
}
for(i=left;i<=right;i++){
ptr[i]=data[i];
}
}
void mergesort(int *ptr,int left,int right,int *data)
{
if(right>left){
int mid=(left+right)/2;
mergesort(ptr,left,mid,data);
mergesort(ptr,mid+1,right,data);
merge(ptr,left,mid,right,data);
}
}
void sort(int *ptr,int n)
{
int *data=(int *)malloc(n*sizeof(int));
mergesort(ptr,0,n-1,data);
free(data);
}归并排序算法排序
- 时间效率:O(nlog2n)
- 空间效率:O(n)
- 稳定性:稳定
基数排序
基数排序基本思想:分配+收集
设置若干个箱子,将关键字为k的记录放入第k个箱子,然后在按序号将非空的连接
基数排序:数字是有范围的,均由0-9这十个数字组成,则只需设置十个箱子,相继按个、十、百…进行排序
void sort(int *ptr,int n)
{
int (*p)[n];
int t[10];
p=(int (*)[n])malloc(sizeof(int)*10*n);
int key;
// 支持十位数以内的排序
int m=10;
int num=1;
int w=0;
int k=0;
int l=0;
int flag=1;
for(int i=0;i<10;i++){
t[i]=0;
}
for(int i=1;i<=m;i++){
for(int j=0;j<n;j++){
key=ptr[j]/num%10;
if(key!=0){
flag=1;
}
p[key][t[key]]=ptr[j];
t[key]=t[key]+1;
}
if(flag==0){
m=0;
}
num=num*10;
for(k=0;k<n;){
while(t[l]==0){
l++;
}
while(t[l]!=0){
ptr[k++]=p[l][w++];
t[l]--;
}
w=0;
}
l=0;
}
}- 时间效率:O(k*(n+m))
- k:关键字个数
- m:关键字取值范围为m个值
- 空间效率:O(n+m)
- 稳定性:稳定
排序总结
时间性能
- 时间复杂度为O(nlogn)的办法有:
- 快速排序、堆排序和归并排序,其中以快速排序最好
- 时间复杂度为O(n2)的有:
- 直接插入排序、冒泡排序和简单选择排序,其中以直接插入为最好,特别是堆哪些堆关键字近似有序的记录序列尤为如此
- 时间复杂度为O(n)的排序方法只有:基数排序
- 当待排记录序列按关键字顺序有序时,直接插入排序和冒泡排序能达到O(n)的时间复杂度;而对于快速排序而言,这是最不好的情况,此时的时间性能退化为O(n2),因此时应该尽量避免的情况
- 简单选择排序、堆排序和归并排序的时间性能不随记录序列中关键字的分布而改变
空间性能
- 所有的简单排序方法(包括:直接插入、冒泡和简单选择)和堆排序的空间复杂度为O(1)
- 快速排序为O(logn),为栈所需的辅助空间
- 归并排序所需辅助空间最多,其空间复杂度为O(n)
- 链式基数排序徐附设队列首尾指针,则空间复杂度为O(rd)